大規模言語モデル(LLM)をローカルで動かすための環境はここ1-2年で急速に整備された印象です。ただ、Windows + Radeon GPU環境での情報はあまり多くありません。このポストではLemonade Serverを利用してWindows + Radeon のLLM実行環境(ROCm/Vulkan)を用意する方法を説明します。
AMD RadeonシリーズのLLM環境
機械学習の環境においては、多くのライブラリ・プログラムはNVIDIAのCUDAライブラリに依存しています。ただLLMの実行環境においては、広く使われているllama.cppがVulkanという3Dグラフィックライブラリを使ったGPU実行に対応しており、VulkanはAMD Radeonシリーズをサポートしているため、WindowsやLinuxではllama.cppを使うことで各種LLMをRadeonで動かすことが可能です。
Vulkan以外のライブラリとしては、AMDが開発するROCmがあります。これは機械学習の包括的な環境を提供するもので、大まかにはCUDAと同じ領域をカバーします。ROCmの方が(理屈上は)VuklanよりもAI用途に最適化されているはずですが、Windows上でROCmを使うための環境がそろっていなかったり、最近までROCmでRadeon 9000シリーズを正式サポートしていなかった等、WindowsでROCmを使うにはやや敷居がありました。
最近になってROCmがRadeon 9000シリーズを正式サポートするようになり、また、llama.cppのフロントエンドでAMD環境を広くサポートした Lemonade Server が登場してWindows上でのROCmとVulkan両方をサポートするようになったおかげで、 Windows + Radeon + ROCm or Vulkan 構成が簡単に利用できるようになりました。
Lemonade Server
Lemonade Server は、比較的新しいOSSのLLMフロントエンドで、WindowsとLinuxで動作します。以下のような特徴があります。
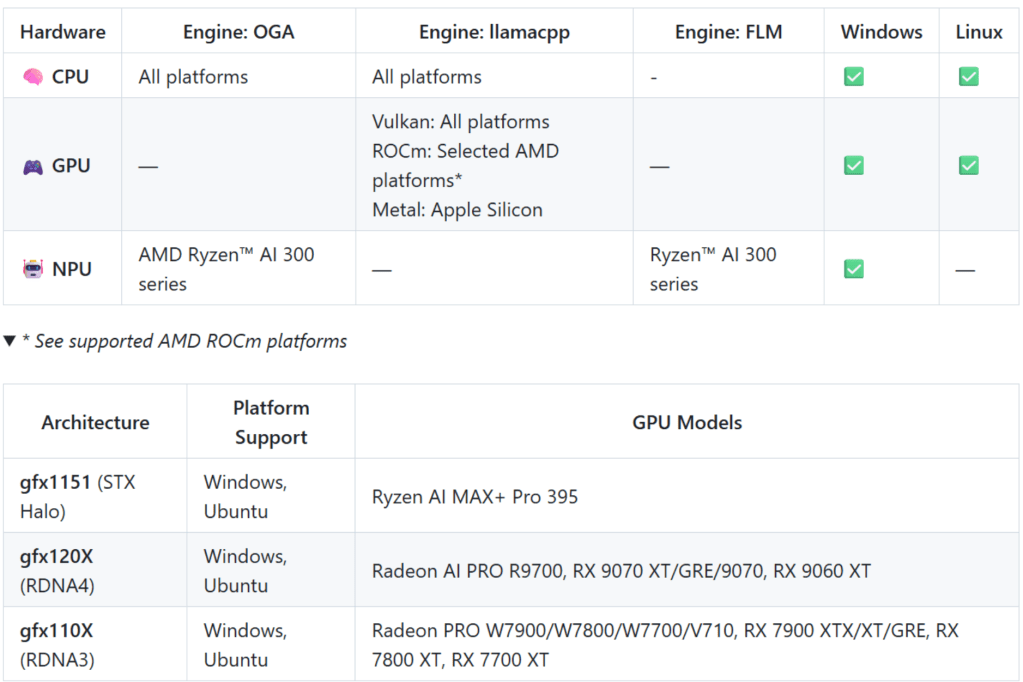
- 複数のLLM実行エンジン(OGA, llama.cpp, FLM)をサポートしており、GPUを使ったLLM実行だけでなく、CPUのみ、およびRyzen AIシリーズに搭載されたNPUを利用した実行にも対応
- llama.cppでは多くのビデオカードをVulkan経由でサポート、一部ビデオカード限定でROCmもサポート(Windows, Linuxともに)
- lemonade-serverやlemonade-router等の主要コンポーネントがC++で記述されているため、高速に動作
類似のソフトウェアとしてはLM Studioがありますが、 それと比較すると、ROCm環境がWindows上で簡単に構築できることや、NPUをアクセラレータとして利用できる点が大きな違いです。Lemonade Serverの開発にはAMDから開発支援を受けているとのことで、そのおかげもあってROCm等やNPU等、AMDの最新環境のサポートが出来ているのだと思います。
WindowsにLemonade Serverをインストールする
WindowsへのLemonade Server導入は簡単です。まずはRadeonのグラフィックドライバ(AMD Software: Adrenalin Edition)を導入し、最新に更新します。
あとは以下のURLにあるLemonade Serverリリース一覧から、最新リリースのmsiファイルをダウンロードして実行するだけです。lemonade.msiとlemonade-server-minimal.msiがあり、lemonade.msiの方がGUIを含むフルセット版、minimalの方はサーバーコマンドだけのものですが、お試し利用にはlemonade.msiの方で良いでしょう。今回はv9.1.0を利用しました。
https://github.com/lemonade-sdk/lemonade/releases
これ以外には(例えばROCmやVulkanのライブラリ、llama.cpp等)導入する必要はありません。上記に同梱されている、もしくは必要な時に自動的にダウンロードするようになっています。
簡単な使い方
インストールするとスタートメニューにLemonade Serverのアイコンが登録されるのでそれをクリックして少し待つとサーバーが起動し、タスクトレイにアイコンが追加されます。タスクトレイのアイコンをクリックすると、登録済LLMのロードや付属GUIアプリケーションの起動が可能です。ここからは私の環境 (Windows 11 + Radeon 9070 XT)での動作を例に説明します。
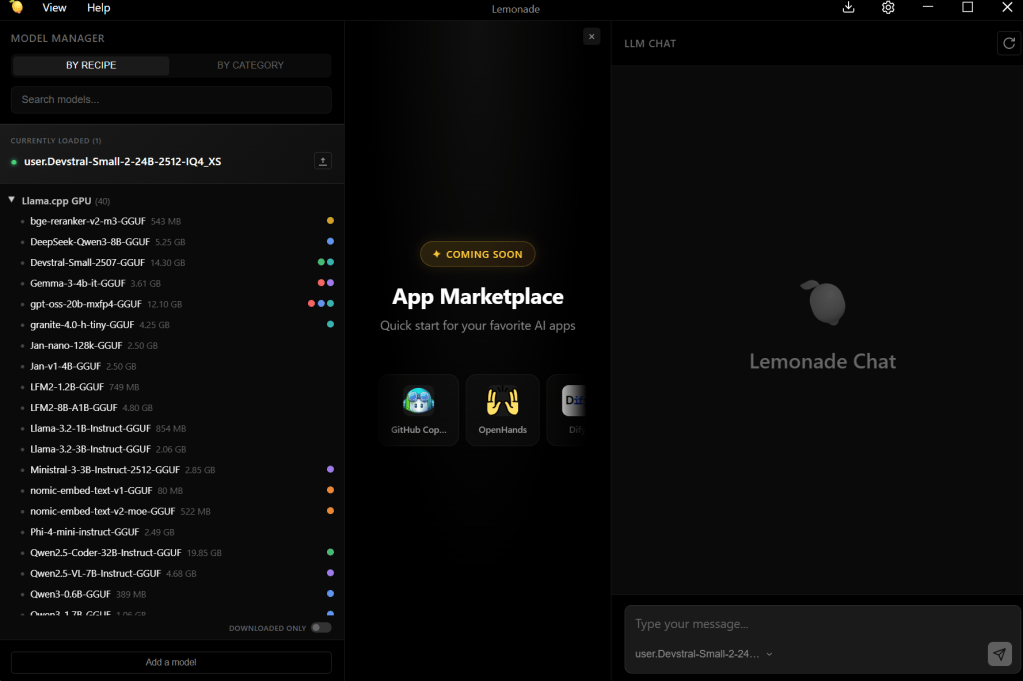
アプリを起動すると、左側にプリセット済のモデル一覧が見えます、私の環境ではRX 9070 XTが自動認識され、llama.cppがGPUでモデルを稼働させるようにセットアップされており、デフォルトではVulkanを利用しています。まずは左の一覧からどれかをダウンロードして実行するのが良いでしょう。
利用したいLLMの名前の上にカーソルを持っていくと、ダウンロードボタンが表示されるのでそれを押すだけでHugging Faceからダウンロードされ、右側のチャット欄でLLMと会話できるようになります。なおダウンロードされたモデルはC:\Users\(ユーザー名)\.cache\huggingface\ 以下に保存されます。
どのLLMが快適に動かせるかは利用するGPUの性能やGPUのVRAMサイズによりますが、おおむねモデルサイズ+1~2GBぐらいが稼働に必要なメモリなので、自分が利用するGPUのVRAMサイズを元に選択してみてください。ただし、後述するようにVRAMにLLMが収まりきらなくても、不足分をメインメモリから確保して動かすことは可能です。一方でメインメモリの利用が多いほど応答スループット(TPS: Token Per Sec)は低下しますので、複数試して必要な要件に合うものを選択するのが良いでしょう。
また、OpenAI v1 API互換のサーバーが8080ポートで稼働しますので、Lemonade Sevrerが起動した状態で、Cline等のアプリケーションからlocalhost:8080を指定すれば、コーディング支援のエージェントとして利用可能です。ポート番号やコンテキストサイズ(デフォルトは4KB)はタスクトレイのアイコンから変更可能です。

プリセットにないLLMを利用する
GUIアプリのプリセットに無いLLMも利用可能です。利用しているエンジンによる対応するモデルフォーマットが異なるのですが、下表にあるようにllama.cppを利用している場合はGGUFフォーマットのモデルが利用できます。
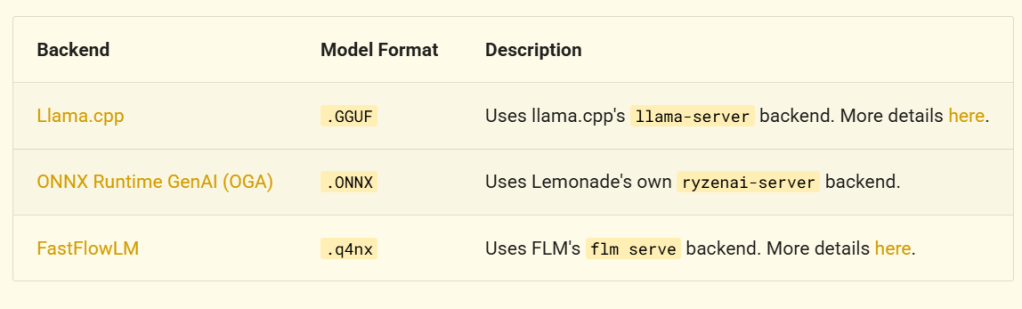
参考) https://lemonade-server.ai/docs/server/server_spec/
LLMは色々なところで公開されていますが、一番有名なのはHugging Faceで、Lemonade Serverもここからのダウンロード、利用をサポートしています。
多数の選択肢がありますが、一例としてコーディングに適しており、日本語も(ある程度)解釈するMisral AiのDevstaral Small 2 (24B)で説明します。以下URLにGGUF版のDevstaral Small 2 (24B)が公開されています。Apache 2.0ライセンスです(利用の前にはライセンスを確認することをお勧めします)。
https://huggingface.co/bartowski/mistralai_Devstral-Small-2-24B-Instruct-2512-GGUF
GGUFのモデルをダウンロードする際に検討するのは量子化(Quantized)の程度です。量子化はパラメータあたりのデータサイズを縮小し、モデルのサイズを縮小する技術です。上記URLでは以下のように量子化されたものが多数用意されており、オリジナルの16bit (BF16)と比較して、4bit等であればVRAM 16GBの環境でも十分収まりそうなほど小さくなっているのが分かります。
一方でbit数が減ると予測精度が劣化しますので、小さくすれば良いということはなく、環境に合わせて、サイズと性能のバランスで決める必要があります。
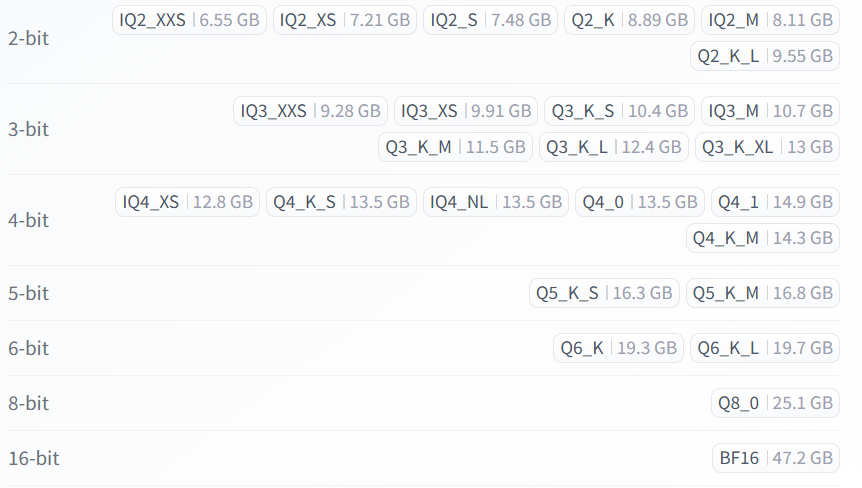
今回はIQ4_QS (12.8GB)を利用します。Hugging Faceからダウンロードする際は、PowerShellを起動して、以下のようにlemonade-server pullコマンドを実行します。
> lemonade-server pull user.Devstral-Small-2-24B-2512-IQ4_XS --checkpoint bartowski/mistralai_Devstral-Small-2-24B-Instruct-2512-GGUF:IQ4_XS --recipe llamacpp
最初の引数の user.Devstral-Small-2-24B-2512-IQ4_XS はローカル保存用の名前でuser.から始めてその後ろは任意の文字列を指定します。–checkpointの後ろの文字列は、Hugging FaceのURLから、:の後ろのIQ4_XSは量子化の説明欄からのものです。
ダウンロードが完了すると、タスクトレーのメニュー等からモデルをLoadできるようになります(別モデルがロード済の場合はそれをUnloadしてからLoad)。ロードが完了したらタスクマネージャのパフォーマンスでVRAM(専用GPUメモリ)の利用率を確認してみてください。

上記のように専用GPUメモリにまだ余裕があることから、LLM(と後述するKVキャッシュ)が、おおむねVRAMに収まっていそうだという事が分かります。もしVRAMに収まりきらない場合は、Windows環境の場合は自動的に共有GPUという領域が利用されます。
この共有GPUメモリは、VRAMが足りないときにシステムRAM(メインメモリ)を一時的に借りて使うための領域を指します。Windows側で必要に応じて自動的に割り当てるため、利用者側は特に何もする必要はないのですが、前述のようにメインメモリに多くのデータが乗ると性能に悪影響が出ます。なお共有GPUメモリはメインメモリ全体の半分まで利用可能です。
なおダウンロードしたLLMは以下のようにして削除可能です。
lemonade-server list ##確認
lemonade-server remove user.xxx ##モデル名を指定して削除
ROCmでの実行
ここまではデフォルトの設定で利用しているため、(私の環境でのデフォルト選択である)llama.cpp + Vulkanで実行されています。ROCmで利用する際はLemonade Server起動のオプションで--llamacpp rocmを指定します。これだけで必要なライブラリをダウンロード、展開し、実行してくれます。
ただしCPU内蔵のGPUと外付けGPUが両方ある環境場合は、内蔵GPUを使わないように指定する必要があります。例えば私の環境のCPUはRyzen 7 9700Xで、この内蔵GPUは0番目のGPUとして、外付けが1番目として認識されています。そのため、ROCmを使うと2つのGPUにモデルを分散ロードしようとして失敗します(内蔵GPUと、外付けGPUで必要なROCmライブラリが異なるため)。
環境変数HIP_VISIBLE_DEVICESで認識させたいGPUを指定しするとこれを解消できます(私の環境では1番目のデバイスを指定する)
また、lemonade-server.exeコマンドの実行にはPowerShell 5.1(Windows 11の標準)を利用してください。PowerShell 7系で実行した場合、ROCmライブラリをダウンロードし展開(Extract)するところでエラーになってしまいました。
# 外付けGPU (Device 1) のみ使用
$env:HIP_VISIBLE_DEVICES = "1"
# Lemonade Server を起動
lemonade-server serve --port 8080 --llamacpp rocm
なお、 --log-level debug を指定してサーバーを起動すると詳細なログが出力されますので、うまく動かない際は指定してみてください。
ROCmとVulkanの簡単な比較
ROCmとVulkanの簡単な比較をしてみます。ちょっと動かしただけのテストですので、あくまでご参考まで。テスト時のコンテキストサイズはすべてデフォルトの4KBです。
VRAMに収まりきるサイズのLLMの場合
前述の4bit量子化(IQ4_XS)したDevstaral Small 2 (24B)で試したところ、
- ROCm : 40-42 TPS前後
- Vulkan : 30 TPS前後
と明確な差が出ました。このモデルではROCmを利用するメリットがあると言えそうです。
VRAMに収まりきらないサイズのLLMの場合
こちらでは、以下で公開されているQwen3-Coder-30B-A3B-Instruct-GGUF (Q4_K_M)を利用しました。ダウンロードしたモデルだけで18GB超あり、VRAMには収まりきらないサイズです。 ただしこのモデルは推論時にアクティブになるパラメータは3Bになる仕組み(MoE)のため、計算量自体はずっと少なくすむはずです。
https://huggingface.co/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF
このLLMの場合、以下のようにROCmとVulkanで差が出ませんでした。ややVulkanの方が速いですが、プロンプトの解釈にランダム性があり、常に同じ回答が得られるわけではないため、数TPSの差は誤差の範囲と言えそうです。
- ROCm : 47-59 TPS前後
- Vulkan : 50-60 TPS前後
推測ですが、VRAMに収まらずメインメモリに格納されたことで、計算のボトルネックがPCIバス経由でのGPU – メインメモリ間通信になり、ROCmかVulkanかといった違いが出なくなっているのではと思います。実際、以下のように共有メモリに数GBはみ出しています。

一方で、数GBメインメモリ側にはみ出しても50-60TPS程度出たのは予想外で(MoEのおかげだとは思いますが、もっと性能が低下すると思っていました)、個人的には十分な速度です。ただ、これはコンテキストサイズが4KBであることも影響しており、これを大きくすると利用メモリが増え、メモリアクセス量が増えることでスループットが低下すると思われます。
なお、ROCmよりもVulkanの方がこれまで使われてきた期間が長く、情報の蓄積量も多いでしょうから、両者で性能が変わらないのであれば、デフォルトのVulkanを利用するのが良いでしょう。
コンテキストサイズやKVキャッシュの調整
コンテキストサイズや、KVキャッシュの量子化もコマンドラインから可能です。
KVキャッシュ(Key–Value Cache)は、LLM(Transformer)が過去に処理したトークンの Attention 計算結果をキャッシュしておく仕組みです。コンテキストサイズはデフォルトの4Kではコーディング支援用には厳しいのですが、これを増やすと、GPU使用率だけでなくKVキャッシュの消費量が増えてしまいます。
そこで、KVキャッシュを量子化することでメモリ利用量を削減し、その分コンテキストサイズを増やすという事を試しました。もちろん量子化による性能劣化の課題もありますが、一般的なGPUであればKVキャッシュの量子化は検討する価値があると思います(もしくはLLM自体をもっと小さいサイズのものにするか)。
私の場合は以下のようなオプションで起動することでコンテキストサイズを32KBにしています。
$env:HIP_VISIBLE_DEVICES="1"
lemonade-server run user.Devstral-Small-2-24B-2512-IQ4_XS --port 8080 --log-level info --llamacpp rocm --ctx-size 32768 --llamacpp-args "--flash-attn on --parallel 1 --no-mmap --cache-type-k q4_0 --cache-type-v q4_0 --ubatch-size 256"
最後に簡単に引数・オプションを説明すると、以下の通りです:
- lemonade-server run : サーバーを起動した直後に指定モデルをロードする指定
- –llamacpp rocm : ROCmを利用
- –ctx-size 32768: コンテキストサイズ 32KB
- –llamacpp-args : この引数部分をllama.cppに渡す指示
- –flash-attn on : フラッシュアテンションをON(デフォルトのAUTOでONになるのですが念のため)
- –parallel 1 : 同時実行数を1に
- –no-mmap : MMAPを使わず、通常のファイルロード
- –cache-type-k q4_0 –cache-type-v q4_0 : KVキャッシュをQ4_0に量子化
- –ubatch-size 256 : GPUに実行させる1計算単位あたりのトークン数
KVキャッシュ量子化についてはQ4_0まで下げて性能にどの程度インパクトがあるのかまだ分かっていないのですが、トークンを32KBにした場合Q4_0まで下げないとVRAMからあふれてしまったため、この値にしています。–no-mmapは、Windows環境ではこれを付けることで動作が安定する(その代わりロードが遅くなる)という記載を見つけたのでつけていますが、今のところ効果は不明です(そもそもVRAMしか使っていない場合はMMAPの設定は関係ないはずです)。
また、個人的な経験では、LLMが大量のVRAMを確保したままの状態でWindowsをサスペンド、レジュームするとその後OSが不安定になることが多く、基本的にはサスペンド前にはLemonade Serverを停止するようにしています。
なお、上記のオプションで実行した場合、以下のように若干共有GPUメモリ(メインメモリ)の利用量が増えているのですが、同じ設定でllama.cpp server単体で起動した場合はほぼ共有GPUメモリを消費ませんでした。つまりLemonade ServerのUI等他コンポーネントで消費しており、LLM本体やKVキャッシュはVRAMに乗り切っていると思われます。実際、32KBのコンテキストサイズで40TPS程度出ており、ここからもVRAMに乗り切っているように見えます(VRAMからはみ出ると10~20TPSまで低下するため)。





コメントを残す