この記事は、AWS Analytics Advent Calendar 2022 の17日目のエントリーです。
AWS Lake Formationというサービスをご存じでしょうか?AWSをお使いの方であれば名前ぐらいは聞いたことがあるという方は多いかもしれません。またその名称から「データレイクを管理するサービスかな?」というイメージをお持ちの方も多いと思います。実際、Lake Formationはデータレイク管理をする人を楽にするためのサービスと言えます。
一方、Lake Formationは多機能であるため、興味はあるけど何ができるのかを掴み切れず手を出しづらいと考えている方も多いのではと思います。本記事ではそういった方に短時間でLake Formationの概要・メリットを掴んでいただけるよう、機能を網羅するのではなくサービスの意図や押さえておきたい考え方を5つのポイントで説明します。
ポイント1:AWS Lake Formationはデータレイク管理を楽にする
AWSのサービスはよく「ビルディングブロック」に例えられます。モノづくりのための便利なパーツであり、自由に組み合わせて開発に使うというイメージですね。一方でLake Formationはビルディングブロックというよりは、データレイク運用管理を支援するためのサービスと捉えると良いでしょう。
想定される主な利用ユーザーはデータレイク管理者です。ここで言う管理とは、例えば各種データソース(RDB等)からデータを定期的にS3に取りこんでデータカタログを維持したり、そのカタログベースを元にユーザからデータへのアクセス権限を管理するという事です。一方でデータへの高速なクエリ等はLake Formationとしては機能をもっていません。あくまで管理が主機能であり、その他にデータレイクに必要な機能な別サービスと協調して実現します。
ポイント2:AWS Lake FormationはAWS Glueと協調して成り立っている
Lake Formationは色々な機能を提供していますが、その一部はGlueの機能を活用して提供されています。例えばLake Formationには、データソース(RDB等)から定期的にデータをS3(データレイク)に転送するためのジョブを数クリックで構築するブループリントという機能がありますが、これはGlue Workflowを使って実行されています。ユーザの代わりにLake FormationがGlue JobやGlue Workflowを作成してデプロイしているのです。
また後述するようにLake Formationはデータレイク上のデータに対し、粒度の細かい(行列単位の)アクセスコントロールを提供しますが、このデータを管理するためのカタログ(データカタログ)はGlue Catalog上の情報をもとに提供されています。
Glue Catalog上にエントリを追加するとLake Formationのカタログにも同じものが現れたり、Lake Formationでブループリントを作成した際の管理画面がGlueにリンクしているのはこういった理由からです。
ポイント3:Lake Formation Permissionで複数サービスにまたがったアクセス制御を一貫性のある操作で実現する
ポイント1に書いたように、Lake Formationの狙いはデータレイク管理の管理業務を楽にすることです。そのために導入されたのがLake Formation Permissionと呼ばれる新しい権限管理の概念です。一般的にAWSリソースのアクセス制御はIAMで行いますが、これをデータレイク管理者が理解して設定するのは時間がかかります。各サービスごとに IAM Policyのアクションは異なり、それらを理解したうえで実装する必要があるためです。
これをより容易に実現するため、Lake Formation PermissionではいわゆるRDBのGRANT/REVOKEと同様のコマンド、もしくはRDBの管理GUIのような操作でアクセス権限をコントロールできるようになっています。
そして、Lake Formationで設定したアクセス権限は、Lake Formationが対応するサービスからのアクセス時に反映されます。つまり、複数のサービスからのアクセス制御をLake Formation Permissionの一か所で統制できるという事です。
ポイント4:対応するAWSサービスとLake Formationで連携してアクセス制御を実現
ポイント3にあげた「一か所で複数サービスにまたがったアクセス制御」はどのようにして実現しているのでしょうか。これはAWSドキュメントから図を引用して説明します。(下図)
- 図の1.はデータレイク管理者です。アクセス制御のための設定をLake Formation上で行います
- 2.はユーザのアクセスです。ユーザはAthenaやEMRに直接アクセスしており、Lake Formationを意識していない事がわかります
- 3.と4.がLake Formation Permissionを実現している部分で、3.にあるように各サービスは一旦Lake Formationにユーザーの権限を問い合わせています。そして権限チェックしてOKでれば、4.でテンポラリーのクレデンシャルをAWSサービスに渡します。サービスはこのクレデンシャルを使用してデータレイク(S3)にアクセスをします。

この図から分かることは、Lake Formationは上図のような協調作業に対応したサービスを利用した際にアクセス制御が実現できるという事です。(補足:図にはAmazon QuickSightがありますが、現状ではAthenaを経由したダイレクトアクセス時のみの対応です。またAmazon RedshiftはRedshift Spectrumのデータのみの対応です)
連携可能なサービスは今後も増加していく予定です。たとえば先日のre:Invent 2022では、RedshiftのData Sharingを行う際にLake Formationと連携できるようになるプレビューが発表されています。
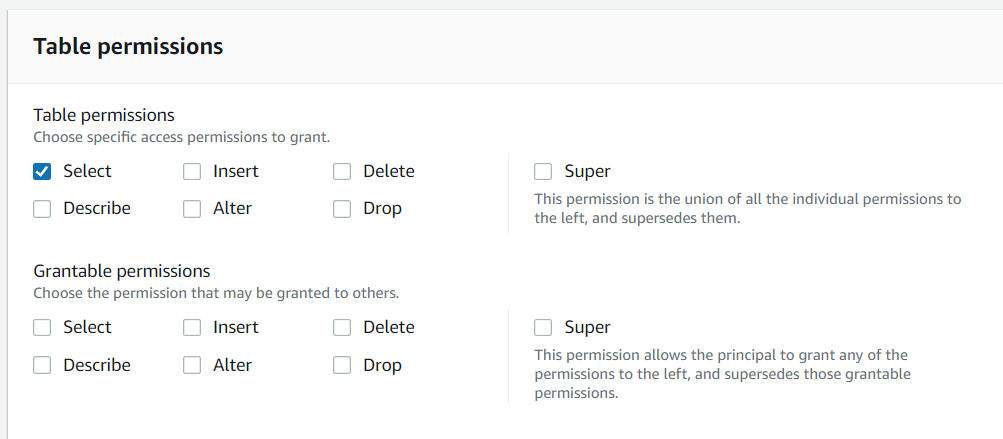
ポイント5:行・列レベルのアクセスコントロールを提供する
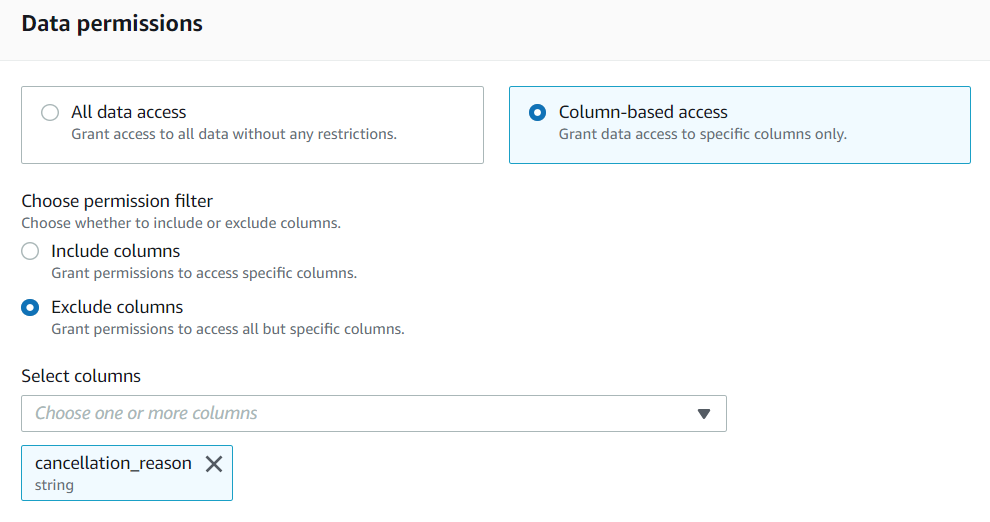
アクセス権限管理の観点で、Lake Formationを利用するもう1つのメリットが、行・列レベルでのアクセス制御です。データレイク(S3)上のデータにIAM Policyでアクセス制御する場合、そのデータ(ファイル)全体を読み取りできる・できない、の二種類しかありません。
Lake Formation Permissionはこれを拡張して、行・列レベルのアクセスコントロールを提供します。つまりユーザAは、表T1の全列を読み取ることができるが、BはT1の一部の列しか読み取れないといった設定を可能にします。行レベル、列レベルの組み合わせも可能なのでセルレベルでのコントロールが出来ると言えます。
これも、ポイント4にあげたようにAWSサービスとの協調で行われています。つまりAWSサービス(Athena等)とLake Formationで協調して不要なデータをフィルタしています。
まとめ
この記事ではAWS Lake Formationとはなにか?を5つのポイントにまとめました。まだまだ説明していない機能はたくさんありますが、データレイク管理をほかAWSサービスと連携しながら支援することで、データレイク管理者はより容易に、より細かな制御を実現できるという事を把握していただければ十分です。
興味を持たれた方は、以下のAWS Lake Formation Workshopを見ていただければと思います。Lake Formationの基本的な機能を一通り確認することができるようになっています。




コメントを残す