Claude Code、Codex CLI、OpenCode等のAIを使ったコーディングはすっかり一般的になりました。(※なおタイトル画像はAIに作ってもらいましたが、この文章は100%人間が書いています。)
※2026年6月10日更新
一方でAIコーディング活用の壁は大規模言語モデル(LLM)利用のコストでしょう。私の周辺には$100/月や$200/月といったLLMのサブスクリプションにプライベートで加入している人がたくさんいますが、これはかなり例外的で、業務ならともかく趣味のコーディングならせいぜい数千円/月ぐらいで始めたい人も多いのではと思います。
この投稿ではOpenCodeで安価にAIコーディングをはじめる – おすすめ構成($0~$30/月)で紹介したパターンのうち、$10/月、$30/月のパターンを例に、どのように節約する(=トークンの消費を抑える)のが良いかというのを自分の経験(実践)の範囲で説明します。
また、昨今はサブスクリプションの値上げ、もしくは利用量の縮小の傾向があり、$100/月プランを利用の方でもトークンを節約する方法を知ることはメリットがあるかと思います。
費用を抑えるための考え方
費用を抑える方法としては、トークンを無駄に増やさないことと、LLM(モデル)の選択が考えられます。
従量課金のLLM APIサービスではトークン(≒LLMとの間でInput/Outputする情報量)に比例してコストが発生します。これはサブスクリプションでも同じで、多くのトークンを利用すると、5時間・週次といったサブスクリプションの利用制限に到達するのがより早くなります。そのためトークンを無駄に増やさないことは重要です。
ただし、多くの推論プロバイダ(LLMをサービスとしてAPIで提供している企業)ではキャッシュの仕組みがあり、キャッシュヒットした部分は安価に利用できます。つまりトークンが倍になったからといって費用やサブスクリプションの利用量が倍になるわけではありません。一般的にコーディングはキャッシュヒット率が概ね90%以上と言われています(私の経験上も90%以上になっていることが多いです)。
また、モデルの選択も重要です。以下はOpen AIのAPI料金表からの引用ですが、同じGPTでも、5.4と5.5では単価が異なりますし、5.4でもminiやnanoといった、性能は劣るものの安価なモデルが用意されています。キャッシュヒット時は単価がそれぞれ1/10になっているのもわかります。
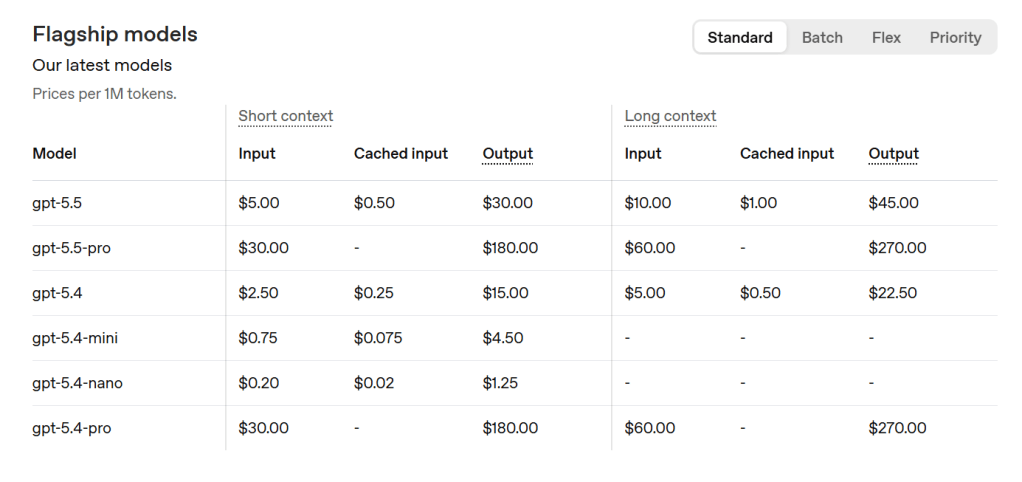
以下は DeepSeek V4 の料金表からの引用です。価格が2つありますが、左がDeep Seek V4 Flash (軽量モデル)、右がV4 Pro(高機能モデル)であり、GPTとは大きく異なることが分かると思います。一般的には著名企業の最先端モデルの費用は高めで、スタートアップは低めです。もちろんモデルの性能が異なるので、安ければ良いという物ではないのですが、節約コーディングにはモデルの選択が重要であることが分かります。
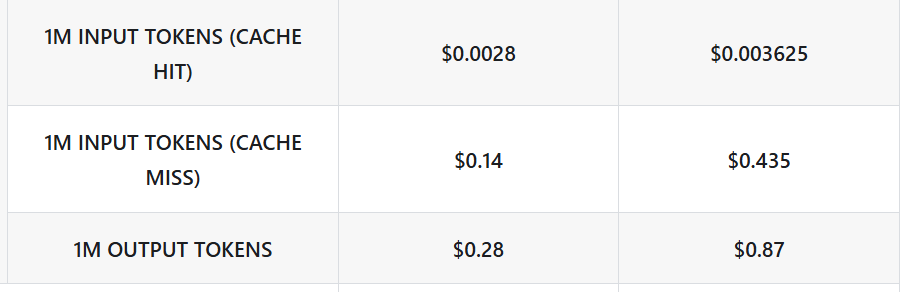
モデル選択の例
多くの方は従量課金ではなく、月額固定のサブスクリプションを選択されると思います。前述の記事で書いたように、$30/月であれば、ChatGPT Plus ($20)+OpenCode Go ($10)、$10で納めるならOpenCode Goが現時点でのお勧めですので、これを例にします。
考え方としては、1/複雑な作業(プラン作成等)、2/メイン(コーディング)作業、3/軽量作業に分けてモデルを選択するのが良いでしょう。つまり基本的には2のモデルを使い、必要なところだけ1を利用、小さい範囲のファイル修正といった軽量作業には3を利用します。
なお本稿の内容からは外れますが、ChatGPT サブスクリプションやClaude Codeサブスクリプションのみで利用する場合は以下のような感じで考えると良さそうです。
- 複雑な作業(プランニング、深い調査): GPT-5.5/GPT-5.4 | Opus 4.7/Sonnet 4.6
- メイン: GPT-5.4-Mini | Sonnet 4.6
- 軽量作業:GPT-5.4-Nano | Haiku 4.6
OpenAIの資料でも、GPT-5.4-Mini, nanoが5.4に近いコーディング性能を出すことが主張されており、miniという名前ながらコーディングに投入してみる価値は高そうです。
ChatGPT Plus + OpenCode Goの場合
この組み合わせの場合のお勧めは、以下の通りです。
- 複雑な作業(プランニング、深い調査): GPT 5.4 OR GPT 5.5
- メイン: GPT-5.4-Mini OR Kimi K2.6 OR MiniMax M3
- 軽量作業:DeepSeek v4 Flash OR Mimo-V2.5
複雑な作業(1)はできるだけ最先端の高性能モデルを活用したいところです。ただ以下のサブスクリプションプランのレート表からわかるように、5.4と5.5では消費クレジットが2倍違います。5.4-miniとの比較では6.67倍です。
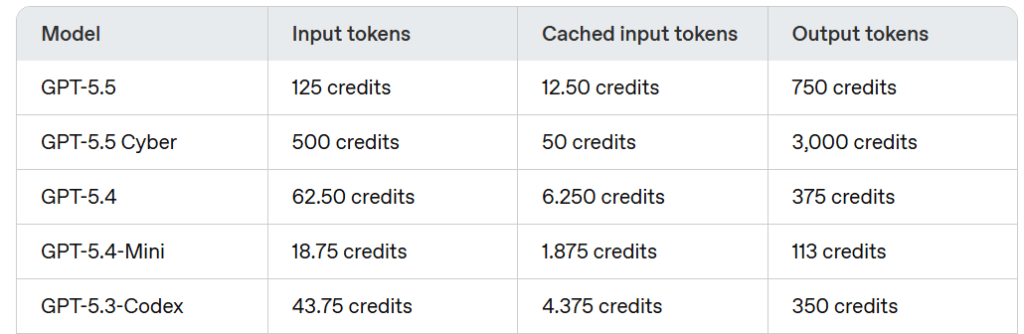
各モデルは性能があがるにつれて無駄な出力をしなくなりますので、この倍率がそのまま消費に反映するわけではないのですが、個人的には$20/月のPlusプランでGPT-5.5を繰り返し使うと、すぐに制限に達してしまう印象です。以前はGPT-5.3-Codexが利用できてこれが価格性能比良好だったのですが、2026年6月からChatGPT Plusでは利用できなくなりました。そこで(1)では、5.4もしくは制限に余裕があるときは5.5を利用し、(2)は5.4-miniをメインに使い、うまくいかない時に5.4や5.5に切り替えています。
なお、GPTやClaudeの各モデルは、thinking (どれぐらい深く考えるか)を low / medium / high / xhighといった形で変更できますが、常にxhighにするのはお勧めできません。私の限られた経験の範囲ではありますが、長く考えても良い結果が出るとは限りません。むしろ間違った方向で長く考えたことで、応答が遅くなり、トークン消費が大きくなる場合もあります。GPT 5.4/5.5に関してはデフォルト(medium)から試すのが良いでしょう。5.5は性能が上がったことでむしろlowもしくはthinking無しに設定しても十分という意見もあります。
意識して節約してもGPT Plusプランだと5時間制限にあたる事がしばしばあり、その場合はOpenCode GoのKimi K2.6やMiniMax M3を利用しています。OpenCode Goは利用できるモデルが多数あるので選択に悩むところですが、個人的にはKimi K2.6がコスト・パフォーマンスのバランスに優れていると感じました。コンテキストサイズ(どれだけ多くの情報を一度に処理できるか)が256KBで、マルチモーダル対応のため図を読むこともでき、汎用性が高いです。MiniMax M3は最近価格が引き下げられた事でKimi K2.6より多く利用できるようになりました。マルチモーダル対応でコンテキストサイズが1MBあるのでKimi K2.6ではコンテキストサイズが不足する場合に有用です(まだ使い込めていないのでどこまで両者で差が出るかは分かっていません)。
軽量作業(3)は、DeepSeek V4 Flashが最適です。驚くほど安いので使ってもあまりGoの利用枠が減っていかないのに、結構複雑なコーディングやデバッグにも耐えられる性能を持っています。利用するAIコーディングエージェントにもよりますが、スラッシュコマンド、サブエージェント単位で利用するモデルを指定できる場合は、軽量作業には自動的に安価なモデルを適用しておくと良いでしょう。(OpenCodeでの例についてはこちらに少し書きました)。また、最近追加されたMiMo-V2.5も、DeepSeek V4 Flashよりわずかに高い費用でマルチモーダル対応のため非常に便利です。
OpenCode Goだけの場合
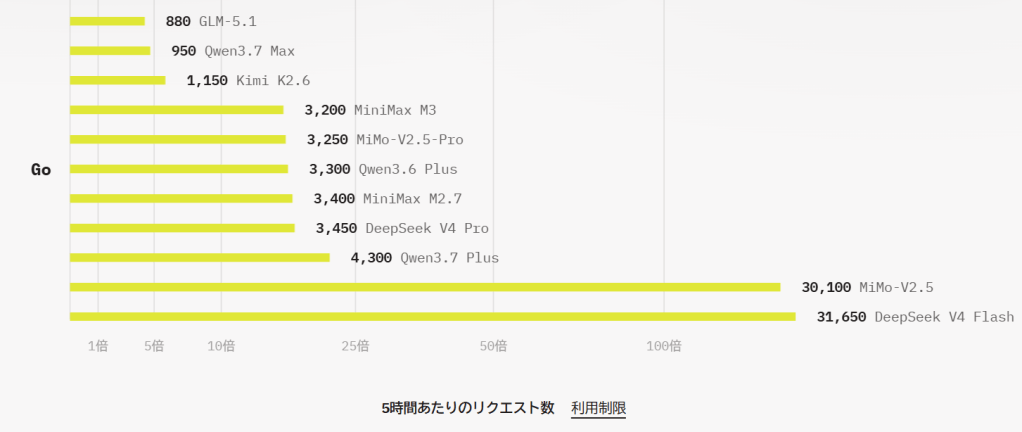
$10/月だけで本当にコーディングできるの?と思われるかもしれませんが、割り切って安価なモデルを積極的に使うことで十分にAIコーディングが実現できます。以下はOpenCode Goホームページからの引用ですが、DeepSeek V4 FlashとMiMo-V2.5の単価の安さが光ります(バーが長いほどたくさん使える)。
$10/月の場合のお勧めは、以下の通りです。
- 複雑な作業(プランニング、深い調査): Kimi K2.6 OR MiniMax M3
- メイン: DeepSeek V4 Flash OR MiMo-V2.5
- 軽量作業:DeepSeek v4 Flash OR MiMo-V2.5
DeepSeek V4 Flashは軽量モデルという扱いですが、驚くほどの範囲の作業がこなせます。プランだけはしっかりと別モデルで作成し、その後は全部DeepSeek V4 Flashに割り振ることでかなりの量のコーディングができます。MiMo-V2.5は最近追加されたのでDeepSeel V4 Flashとどの程度差が出るかはまだ分かっていないのですが、マルチモーダル対応かつコンテキストサイズが1Mあるため、価格の安さと汎用性を合わせもっています。
トークンを節約するためのツール
モデルの選択に加えて無駄なトークンを減らすことも重要です。世の中にはトークン(コンテキスト消費)をコンパクトにするためのツールやフレームワークが多数ありますが、個人的に利用していて効果を実感しているツールを紹介します。
coco-index code
coco-index code (ccc) は、ASTベースのセマンティックコード検索を実現するツールです。事前にコード全体のインデックスを作成しておき、効率的に検索することを実現します。
経験上、ある程度コードベースができてくると、コンテキストの中はTool callの結果で埋まるようになってきます。これはコードを修正・追記するためにエージェントがgrepでコードを検索し、読み込むという行為を繰り返すことが理由の1つです。
cccで事前にインデックスを作成しておくと、例えば認証ロジックがどこかを検索する場合はgrepするのではなく ccc search "authentication logic" というような形でcccを呼び出すことでロジックの箇所を瞬時に得ることができ、grepを繰り返したり、無駄なファイルを読み込んだりしてコンテキストを消費するという事を減らしてくれます。
昨今のAIコーディングツールはこういった検索をサブエージェントにやらせることで、メインエージェントのコンテキストを消費しない工夫がされているものが多いですが、サブエージェント側でトークン使用が減りますし、メインエージェントもすべてをサブエージェントに移譲するわけではありません。何より検索速度があがることで全体の処理自体が短くなる効果があります。
インデックスの作成にはEmbeddingという処理を行えるLLMが必要なのですが、ごく軽量な(CPUで動く)モデルが内蔵されていますので別途LLM契約なしで利用できますし、AWSやOpenAIがEmbed用のモデルをすごく安価に提供しているので、そちらを使っても費用はほとんどかかりません。同様のツールは複数ありますが、個人的にはこのcccが使い始めるのも簡単でお勧めです。
RTK
RTK は、対応しているコマンドラインの出力からAIの処理に必要ない部分をカットすることで、tool callのコンテキスト消費自体を抑えるツールです。
多くのコーディングツールには/compactコマンドがあり、これを使うことでコンテキスト自体を要約してサイズを削減することができるのですが、あくまで要約なので細かい部分が失われます。また、次のInputはキャッシュにヒットしなくなってしまいます。
一方でRTKはAIに必要ない情報を事前にカットするというアプローチなので、副作用が少ないところがメリットです。例えばgit statusを例にすると、以下のようになります。必要な意味だけにそぎ落とした感じになっているのが分かりますね。
#rtkなし> git statusOn branch mainYour branch is up to date with 'origin/main'.nothing to commit, working tree clean#rtkあり>rtk git status* main...origin/mainclean — nothing to commit
私の利用範囲だと (Rustの) cargo で節約効果が大きいです。cargo testの出力は結構大きいし、エージェントが開発の過程でtestを繰り返すためです。一方でRTKだけで劇的な削減効果が得られるわけではない点には注意が必要です。AIのコンテキスト消費は、コーディング時のファイルの検索と読み返しの方が圧倒的に多く、コマンドライン出力が主ではないためです。また、強制的にrtkを挿入することによる副作用もゼロではありません。
Context7
後で書くSDDにもつながる話ですが、エージェントに無駄な処理をさせないことは、コーディング品質を上げるだけでなく節約の面でも重要です。つまり、適切な参考情報にすぐアクセスできるようにしておくという事ですね。
そういった事を補助するツールも多数あるのですが、Context7は以前からの定番であり、現在でも大変有用なツールです。MCPを設定するだけでエージェントが最新の(OSSの)ドキュメントやAPI仕様を把握し、正確なコードを短時間で出力できるようになります。
MCPを使うとコンテキスト消費が大きいのでは、と思われるかもしれませんが、Context7は去年(2025年)末の改善で大幅にコンテキスト消費が抑えられる形にデザイン変更されており、コンテキスト消費をあまり気にせず利用できます。
Spec-driven Development (仕様駆動開発)を適用する
Spec-driven Development (SDD)は、先に仕様(プラン)をしっかり固めたうえで、エージェントにその仕様そって開発させることで、安定した品質のコード生成を行うための手法です。AWSがKiroをリリースした事をきっかけに広く知られるようになり、色々なSDDフレームワーク・ツールが利用可能になっています。
SDDはエージェントとの会話を繰り返して仕様を固めるため、そこでトークンを消費するのですが、その後のコーディングのところではエージェントの迷いが減り、品質向上だけでなく、トータルでのトークン削減につながります。
また、前述の用途に応じたモデル切り替えとも相性が良いです。つまり仕様固め(プランニング)は、高性能なモデル(1)で行い、実際のコーディングやデバッグは(2)や(3)のモデルで行うという方法であれば、モデルを頻繁に切り替える必要もなくなります。
SDDのフレームワークはそれぞれ特徴があるので、好みのものを試してみるのが良いと思いますし、最初はコーディングエージェントに付属の”Plan”モードの利用だけでも問題ないと思いますし、シンプルに導入できる”grill-with-docs“のようなスキルを使って計画を資料化するのも良いと思いますが、私が使った範囲でお勧めできるのは以下の2つです。
- OpenSpec : 比較的コンパクトで理解がしやすく、すでに構築が進んでいるプロジェクトに途中から適用することにも柔軟に対応できます。
- cc-sdd: kiroを意識した形で作られたフレームワークです。やや重めのフレームワークですが、仕様固めの中でしっかりとバウンダリー(どこまで作るか作らないか)を定義し、TDDスタイルでの開発を行う形になっています。
どちらも仕様がファイルとして残り、どこまで対応したか等もファイル上で管理します。そのため、仕様が決まったらいったんセッションを切り替え、新しいセッション(トークン消費していないセッション)で開発をすることができます。
もちろん、常にSDDを適用すれば良いというわけではないです。シンプルな機能追加、修正であれば、仕様を作るコストをかけずにエージェントに指示した方が安く・早く済む場合があるため、使い分けが重要です。
まとめ
想定より長くなってしまいました。現在空前のAIブームということもあり、毎日のように便利なツールが生まれています。上記はあくまで私の経験の範囲でしかないので、ぜひ色々と試してみてください。
個人的にはもう少し踏み込んだトークン削除(剪定)ツールも今後試そうと思っています。キャッシュが無効化されることとのバランスではあるのですが、上記ツールを入れていてもやはりtool callの量がコンテキストの多くを占めているためです。
なにか良い効果を発見したら本稿を更新しようと思います。




コメントを残す