この記事は AWS Analytics Advent Calendar 2021 の7日目の記事です。ここではAWS re:Invent 2021期間中に発表された、Amazon AthenaのApache Icebergプレビューに少し触れてみたいと思います。
Amazon AthenaがApache Icebergデータの読み書きに対応
以下のWhat’s newにあるように、2021/11/29付けでAmazon AthenaでApache Icebergにプレビューとして対応したと発表がありました。 (※追記:その後、2022/4/5に一般提供開始(GA)になりました)
AthenaはS3上に置かれたファイルにSQLでクエリをすることができるサーバーレスのサービスです。対応ファイルフォーマットは多彩で、CSVやTSVだけでなくJSONやORC、Parqurtフォーマット等にも対応しています。しかし、今回のIcebergサポートは単純に対応ファイルフォーマットが増えた(対応SerDeが増えた)のとは少し異なります。Icebergは単なるファイルフォーマットではないためです(後で触れますが、ファイルフォーマットしてはParquet等が利用されます)。IcebergはAmazon S3等のオブジェクトストレージ上に格納されたデータに対し、データを格納するだけでなく、INSERT, UPDATE, DELETEといった処理や、タイムトラベルクエリといった高度な機能を提供するための仕組みです。
S3上のデータを更新可能にするということ
昨今、S3上に多くのデータを蓄積してデータレイクとして利用する設計は一般的になりました。データレイクに多くのデータを蓄積するようになり、それを(Athenaのように)クエリできるようになると、ファイルの蓄積を超えて、行単位の更新処理を行いたいというニーズも増えてきます。
S3上にCSVやParquetでデータを保存した場合を考えると、新しい行の追加はシンプルに実現できそうですが(新しいファイルを作るだけなので)、行単位での更新や削除となると、既存のファイルから該当行を探して処理しないといけないので、効率的に行うにはなんらかの工夫が必要です。
この課題を解決するため、更新処理を容易にするファイル管理方法が色々と考案されています。例えばAWSネイティブサービスでは、AWS Lake FormationのGoverned Tableがそれにあたりますし(詳しくはこちらに)、他にもApache HudiやDelta Lakeも同様です。
そしてこれから試すIcebergも同様の課題を解決するためのものです。
Apache Icebergの特徴(個人的に気になる部分)
Apache Icebergの詳細な機能についてはホームページに任せるとして、個人的に気になるポイントをあげると以下の3つです。
- ハイパフォーマンス
- タイムトラベル(昔の情報をスナップショットとして記録しており、以前のデータがクエリできる)
- スキーマエボリューション(ALTER TABLEで列追加できる)
今回はごく小さいデータを読み書きするだけのテストなのでパフォーマンスは測定できないですが、残りの2つについては、実際に動かして動作を確認してみましょう。特にタイムトラベルは気になりますね。(補足をすると、タイムトラベルクエリのような機能を実現できるのはIcebergだけという事ではありません、例えば前述のLake Formation Governed Tableでも実現可能です。)
AthenaでIcebergを試すための前準備
この機能は現在プレビュー中なので、本番用途には推奨されていないという点には注意が必要です。また利用可能リージョンは、現状バージニア北、オレゴン、アイルランドの3つのみです。今回はオレゴンリージョンで試しました。その他の制限事項・注意事項はこちらのドキュメントを参照してください。
追記:2022/4/6:その後プレビューが終わり、一般提供開始(GA)になりました。そのため、現在は以下にある”AmazonAthenaIcebergPreview”ワークグループの作成は不要になっています。また東京リージョン等、プレビュー対象でなかったリージョンでも利用が可能になっています。
Athenaの管理コンソールにログインし、左側のハンバーガーメニューからワークグループを選択し、新しく”AmazonAthenaIcebergPreview“という名前でワークグループを作成します。この名前のワークグループ上でSQL処理のみIcebergのプレビュー機能が使えるので、必ずこの名前で作成し、クエリエディタ上(右上)で、 AmazonAthenaIcebergPreview を利用するように切り替えておいてください。

続いてクエリエディタから CREATE DATABASE `iceberg` 等でテスト用のデータベース(こちらの名前は任意です)を作成して、左側のメニューから利用データベースを作成したものに切り替えておきます。
また、S3でIcebergのデータを格納するためのバケットを作成しておきます。これで準備完了です。
Iceberg表を作成する
表の作成は基本的には通常のAthenaの表と同じですが、以下のオプションを付けることでIcebergの表になります。
TBLPROPERTIES ( 'table_type' ='ICEBERG')今回は以下のようなシンプルな表(tab1)を作成しました。
CREATE TABLE tab1 (
id int,
data string,
category string)
PARTITIONED BY (category)
LOCATION 's3://(ここにバケット名を入れる)/tab1/'
TBLPROPERTIES (
'table_type'='ICEBERG',
'format'='parquet'
);問題なく作成できました。(私の環境では、GUI上はパーティショニングに指定したキーが重複して表示されてしまっていましたが、後で触れるようにクエリしてみると正しく定義されています)
この時点、S3上はどうなっているでしょうか?CREATE TABLEで指定したバケットをs3-treeコマンドでリストすると以下のようになっていました。
$ s3-tree iceberg-tables-2021
iceberg-tables-2021
└── tab1
└── metadata
└── 00000-bf9c6842-0a04-498b-911b-66c5638f1f4f.metadata.json
メタデータらしきファイルが1つ作られていますね。ではデータを入れていきます。
データをINSERTする
まずは1行インサートしてみます。
insert into tab1 values (1,'ABC','CAT1');少しまつと、クエリが成功するのでSELECTで確認します。
SELECT * FROM tab1;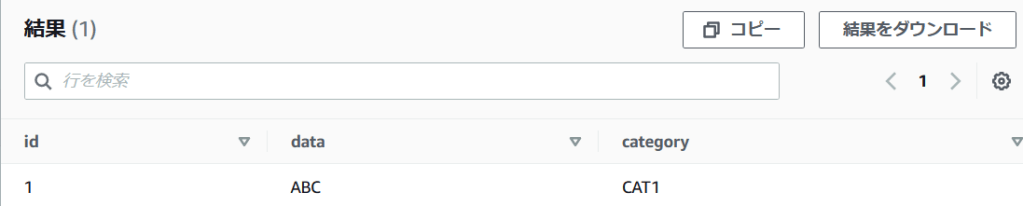
クエリできました。通常のAthenaの表よりはクエリに時間がかかっていますが、これは後述するような高度な機能を実現するためのデータ管理のオーバーヘッドが、たった1行の挿入やクエリだと相対的にすごく大きくなってしまうためでしょう。
ではデータはS3上でどのように保存されているのでしょうか?
$ s3-tree iceberg-tables-2021
iceberg-tables-2021
└── tab1
├── data
│ └── 3b848bd4
│ └── tab1
│ └── category=CAT1
│ └── 245639a4-07f7-470c-9a3b-d332fd6f7d0c.parquet
└── metadata
├── 00000-bf9c6842-0a04-498b-911b-66c5638f1f4f.metadata.json
├── 00001-39278073-bf46-40cf-a2d7-e46891e7fcb5.metadata.json
├── d798e865-1d25-498c-9127-e111cbf8d8a2-m0.avro
└── snap-7013823209212994151-1-d798e865-1d25-498c-9127-e111cbf8d8a2.avroメタデータが増えていることに加え、tab1/の下にdata/というフォルダができ、さらにその下にハッシュ化されたIDらしきものや表名、さらにパーティショニングに指定したキーでフォルダが作成されて(category=CAT1)、最後にparquetファイルとしてデータが保存されていることがわかります。
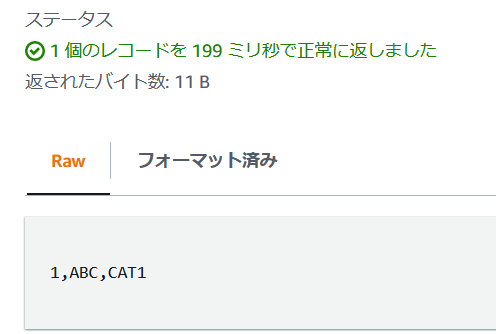
このparquetファイルをS3 SELECTで確認してみると、以下のようになっており、データ保存自体のファイルフォーマットとしてはCREATE TABLE時に指定したようにparquetが利用されている事が確認できます。(Athena側のPreview時点の制約として、ファイルフォーマットはParquetのみの対応です。)
さらに2行追加してクエリします。
insert into tab1 values (2,'DEF','CAT2'),(3,'GHI','CAT1');
SELECT * FROM tab1;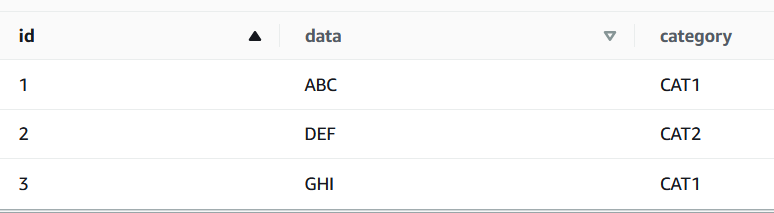
継続的に追記が可能であることが分かりました。この状況でS3を確認すると以下のようになっています。(metadataディレクトリは省略しています)
iceberg-tables-2021
└── tab1
├── data
│ ├── 25396580
│ │ └── tab1
│ │ └── category=CAT2
│ │ └── 1b5cdb69-35f0-43c1-8d41-4c7acb951377.parquet
│ ├── 3b848bd4
│ │ └── tab1
│ │ └── category=CAT1
│ │ └── 245639a4-07f7-470c-9a3b-d332fd6f7d0c.parquet
│ └── 79998f95
│ └── tab1
│ └── category=CAT1
│ └── 9bba08c9-406d-4b66-9643-73797c9df55a.parquetオブジェクトが3つ作成されていることがわかります。つまり、新規にインサートされたデータはもとからあるファイルに結合されるのではなく、別ディレクトリの別ファイルとして管理されています。
データを更新する
続いてUPDATEを試します。
UPDATE tab1 SET data='modified' WHERE ID=3;
SELECT * FROM tab1;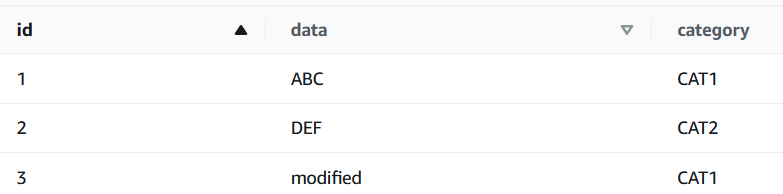
S3上は以下のようになりました。
iceberg-tables-2021
└── tab1
├── data
│ ├── 25396580
│ │ └── tab1
│ │ └── category=CAT2
│ │ └── 1b5cdb69-35f0-43c1-8d41-4c7acb951377.parquet
│ ├── 29a4e287
│ │ └── tab1
│ │ └── category=CAT1
│ │ └── 5e8b9dbc-16f4-42a0-91cf-ac15f5d14451.parquet
│ ├── 3b848bd4
│ │ └── tab1
│ │ └── category=CAT1
│ │ └── 245639a4-07f7-470c-9a3b-d332fd6f7d0c.parquet
│ ├── 44be062e
│ │ └── tab1
│ │ └── category=CAT1
│ │ └── delete
│ │ └── position
│ │ └── 1a4ce4a9-2011-4b1f-a78c-87f6c93d8309.parquet
│ └── 79998f95
│ └── tab1
│ └── category=CAT1
│ └── 9bba08c9-406d-4b66-9643-73797c9df55a.parquet1行更新したら、データを保存するオブジェクトの数が3つから5つに増えました。ただし、 29a4e287/以下に作られたのはこれまでと同じディレクトリ構造のデータですが(中のParquetファイルには更新後のmodifiedデータが入っていました)、 44be062e/以下はディレクトリがdelete/position/となっており、他のファイルと異なることが分かります。このdelete/以下に作られたオブジェクトをS3 SELECTで確認すると以下のようになっています。

つまり、このファイルはどのポジション(位置番号=0)のデータを消したかという記録を管理するためのファイルになっているようです。このことからIcebergでの更新は、新しいデータの挿入と、削除記録の2つによって成り立っていることが類推できます。このように過去のデータは上書きされずに、削除されたという事を含め記録が残るわけですが、この格納方法が、この後試すタイムトラベル機能にもつながります。(DELETEも問題なく動作しましたが、UPDATEと内容が被るので省略します。)
タイムトラベル機能
Icebergでは更新のたびにその状態の表が”Snapshot”として記録され、Snapshot IDや時刻を指定することで、過去の(更新前の)データをクエリできるというのがタイムトラベル機能です。まずSnapshotの履歴(History)を確認してみます。
Athenaで履歴を確認するには、表の名前の後ろに$iceberg_historyと付けてクエリします。
SELECT * FROM "tab1$iceberg_history"
このように、3つのsnapshotがあり、それぞれIDが記録されている事がわかります。parent_idはそのsnapshotの前(先代)のsnapshotを表しています。
では、過去のデータをクエリしてみましょう。UPDATEをかける前のSnapshot IDを”FOR SYSTEM_VERSION AS OF”で指定して以下のようにクエリします。
SELECT * FROM tab1 FOR SYSTEM_VERSION AS OF 4560720481561046026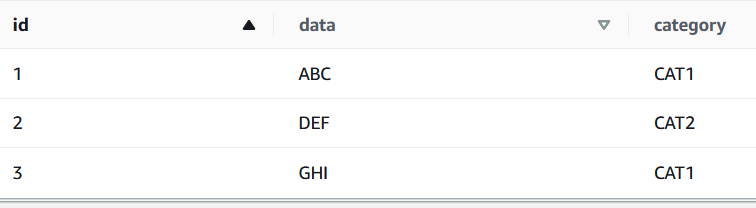
このように、UPDATEを実行する前のデータをクエリすることができました。便利ですね!
この状態でS3を確認すると、/medatadaフォルダが以下のようになっていました。
└── metadata
(中略)
├── snap-4560720481561046026-1-6ac80eb4-3f7e-4637-ab5f-2059fc0e0b84.avro
├── snap-6021433482768829689-1-238c0719-5478-42b7-b713-68fe29a564b4.avro
└── snap-7013823209212994151-1-d798e865-1d25-498c-9127-e111cbf8d8a2.avro
snapshotの数と、metadata/以下にあるsnap-….avroファイルの数が一致しますので、これらのファイルでsnapshotの管理をしているであろう事が推測できます。
スキーマエボリューションで列を追加する
最後にスキーマエボリューションの機能を少しだけ試してみます。
ALTER TABLE tab1 ADD COLUMNS (dummy string);
SELECT * from tab1;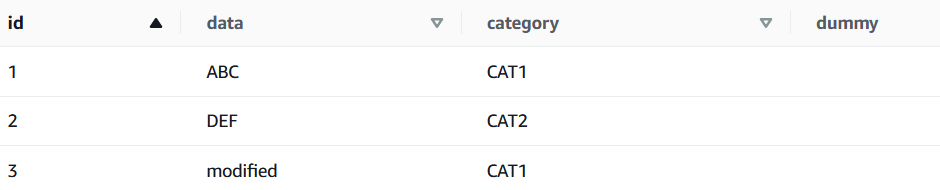
動的にdummy列が追加される事が確認できました。
表を削除する
表の削除はDROP TABLEで行います。
DROP TABLE `tab1`;これでAthena上からは(正確にはGlue Data Catalog上からは)定義が消えます。ただし、S3上のデータは残ったままですので注意してください。
まとめ
AthenaのIcebergプレビュー機能を試してみました。この他にもデータ配置のオプティマイズ機能やトランザクション機能(更新をコミットするまで以前のデータが見える)等もありますので、ぜひドキュメントを参照しながら試してみてください。
また、前述のようにLake FormationのGoverned tableでもS3上でこういったACIDトランザクションや更新、タイムトラベルを実現できるわけですが、こちらにもAthenaは対応しています。クエリの書き方も本記事をほぼ同じ方法で使えますので、ご興味あればぜひGoverned tableも試してみてください。




コメントを残す